Serinin bir önceki yazısında In-Memory DW konseptinde yani ColumnStrore indexlerde yapılan geliştirmelere göz atmıştık. İncelemek isterseniz şu linki takip edebilirsiniz:
http://abdullahkise.blogspot.com/2016/03/sql-server-2016-yenilikleri-1-in-memory.html
Bu yazımızda In-Memory OLTP konseptinde yapılan geliştirmelere odaklanacağız.
In-Memory OLTP, SQL Server 2014 ile birlikte karşımıza çıktı. Bu teknoloji sayesinde INSERT, UPDATE, DELETE işlemlerinde 30 kata varan performans elde etmek mümkün oldu. Konu hakkındaki tüm ayrıntılı bilgileri daha önce paylaşmıştık. Şu linkten inceleyebilirsiniz :
http://abdullahkise.blogspot.com/2014/01/microsoft-sql-server-2014-ctp2.html

Yukarıda linkini verdiğimiz yazımızın sonundaki cümle ile bir özet geçelim :
"Lock ve Latch olmayan. ACID kurallarını destekleyen ve multi-version optimistic concurrency control prensibi ile transactionları yöneten. Verinin memoryde tutulduğu. Arka planda C ve FileStream nesnelerinin kullanıldığı mevcut Database Engine’e entegre yeni bir teknoloji. Bu teknoloji INSERT, UPDATE, DELETE performansını 30 kat arttırmak konusunda iddialı."
Testlerimizde de gördük ki bu teknoloji sayesinde OLTP işlemlerinin performansı etkileyici şekilde artıyor. Ancak paylaşılan istatistiklere göre uyumlu veritabanı oranı %5 civarında görünüyordu. Bunun nedeni kısıtların çok fazla olmasıydı. Neyse ki SQL Server 2016 ile birlikte bu kısıtların bir çoğundan kurtulduk. Son durumda uygulanabilme oranının bir hayli yükseleceğini düşünüyoruz.
Teknoloji trendinin bizi getirdiği noktadan baktığımızda git gide daha modern donanımların yaygınlaşacağını göreceğimiz çok açık. Artık eskiye nazaran daha fazla CPU ve daha fazla memory ile çalışabiliyoruz. Rekabetin artması birim zamanda verilen karar miktarının artmasına sebep oluyor. Karar verme ve operasyon hızının artması için de veri analizinde baş döndürücü bir hıza ihtiyaç duyuluyor.
Şimdilerde devler teknoloji ve matematiği bir araya getirerek bu konularda pratik çözümler sunmaya çalışıyor. Bu çabanın sonucu olan In-Memory OLTP sayesinde RDBMS sistemleri yeni dünya ihtiyaçlarına cevap verebilir hale gelmektedir. Gerçek zamanlı ve/veya düşük gecikmeli analiz, raporlama çözümleri Microsoft, Oracle, IBM vs. gibi bir çok dev tarafından tanıtılmaktadır. Microsoft tarafına odaklanırsak; RDBMS sistemlerinin yaygın, başarılı ve akılda kalıcı çalışma şeklinde pek bir değişiklik yapmadan In-Memory OLTP yi kullanmak mümkün.
Gelelim SQL Server 2016 ile birlikte duyurulan bazı önemli In-Memory OLTP geliştirmelerine;
- In-Memory OLTP kapsamında tanımlanan tabloların (Memory Optimized) maksimum boyutu 256 GB'dan 2 TB'a yükseltildi.
- Artık tablo, procedure, index için ALTER komutları kullanılabilmektedir. Yani Schema da sonradan değişiklik yapılabilir.
- Yeni versiyonda Natively olarak compile edilmiş (C dll) scaler fonksiyonlar tanımlanabiliyor.
- İç içe Natively Compile procedureleri kullanmak mümkün.
- Artık DML trigger tanımlanabilmekte.
- TDE Encryption bu versiyonda destekleniyor.
- Multiple Thread ve Parallel Plan geliştirmeleri ile bir önceki versiyona göre çok daha daha fazla performans elde etmek mümkün.
- OUTER JOIN, UNION, DISTINCT, SubQuery, FOREIGN KEY, CHECK, UNIQUE constraint ve NULL kolon desteği mevcut.
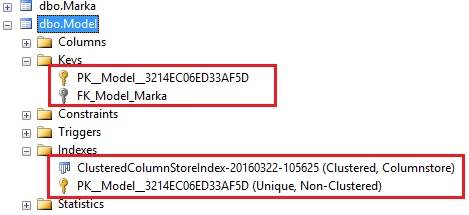
- Nihayet Memory Optimized tablolarda ColumnStore index tanımlanabiliyor. Bu hem yazma hem de okuma performansında şaşırtıcı bir artışın olacağı anlamına geliyor.
- Saniyede 1.2 milyon transaction veya 900 MB/s veri yazma hızına erişilebiliyor.
In-Memory OLTP'nin genel kullanım paternlerine şu linkten erişebilirsiniz:
https://msdn.microsoft.com/library/dn673538.aspx
Yenilikleri buraya kadar özetlersek;
In-Memory OLTP sayesinde INSERT, UPDATE, DELETE performansı 30 kat artıyor. Bu teknojide verinin direk memoryden sunulması, lock ve latch olmaması SELECT performansında da dikkat çekici bir artış sağlıyor. Ancak SELECT performansını asıl arttıran In-Memory DW başlığı ile gelen ColumnStore indexler olmuştur. Bu indexlerin sunduğu performans artışı ise yaklaşık olarak 100 kattır.
In-Memory OLTP ile In-Memory DW bir araya geldiğinde ise ortaya Operational Analytics adı ile duyurulan yenilik çıkıyor. Etkileyici bir tasarım. Bir sonraki yazımızda bu konuya odaklanmayı planlıyorum.